What is Mechanistic Interpretability?
- Attempting to reverse engineer the detailed computation performed by Neural Networks (and now Transformers!)
- Describe the working of these Networks in simpler Mathematical Functions.
What is our Goal?
- Discover Algorithmic Patterns, Motifs, Frameworks which can be applied to larger models
Simplifying assumptions made
- No MLP (Multi Layer Perceptron / Fully Connected Neural Network) Layers
- No Biases in Weights (If at all required we can modify weights creating an additional dimension that is always one but it doesn’t affect any insights discovered in the paper)
- No Layer Norm
Non Standard (but equivalent) Representation of the Transformer
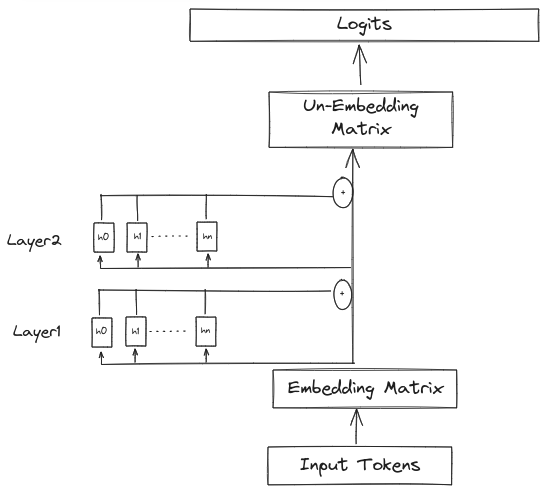
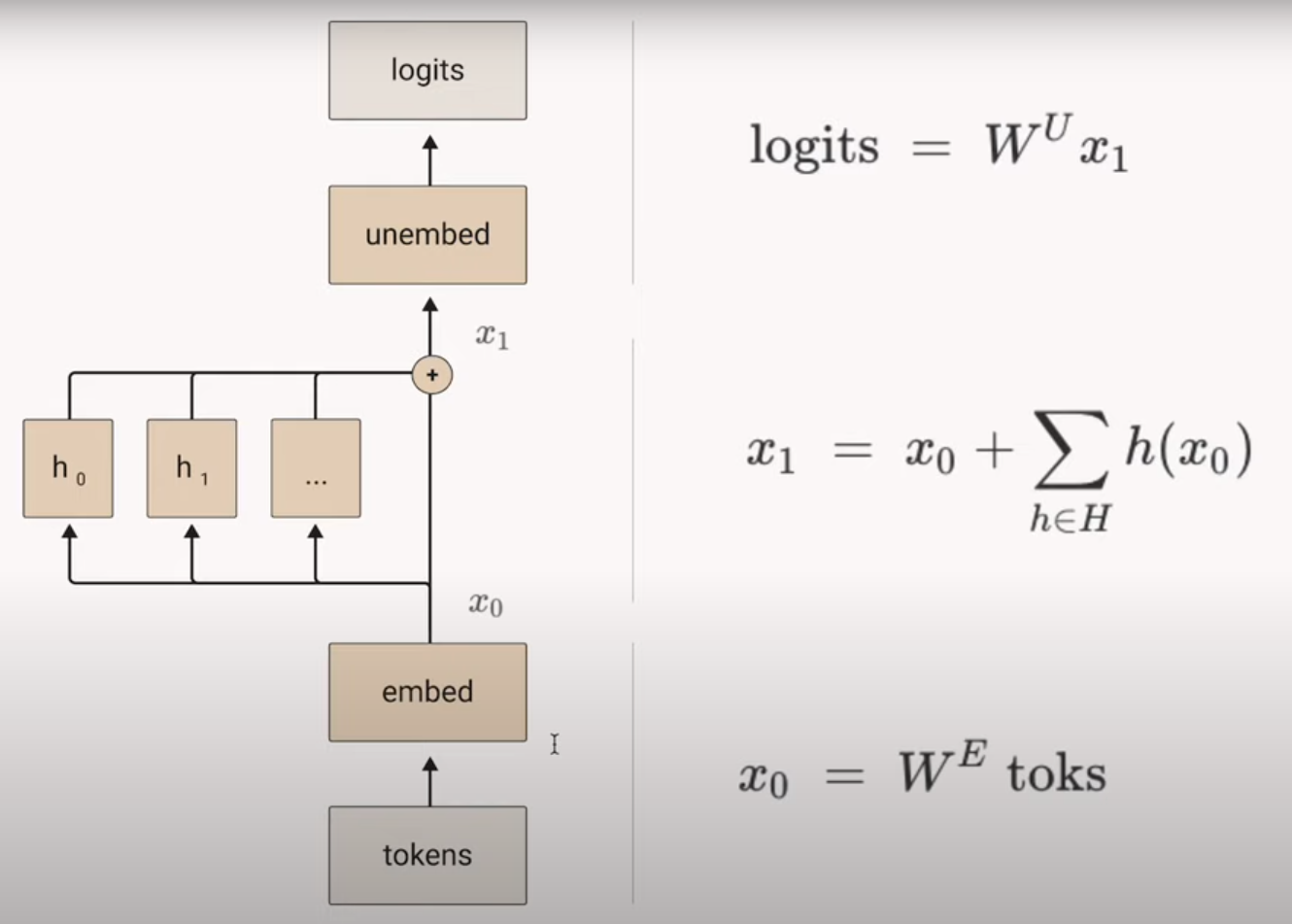
What is the “Residual Stream”?
Zero Layer Attention models Bigram Statistics
Due to the absence of the Attention Mechanism, only the last produced token can influence the production of the next one.
This should mean that the model would try to learn the Bigram Statistics table of the Dataset and use it to produce tokens.
This also means there is no “In-Context Learning” as the context is only the last produced token.
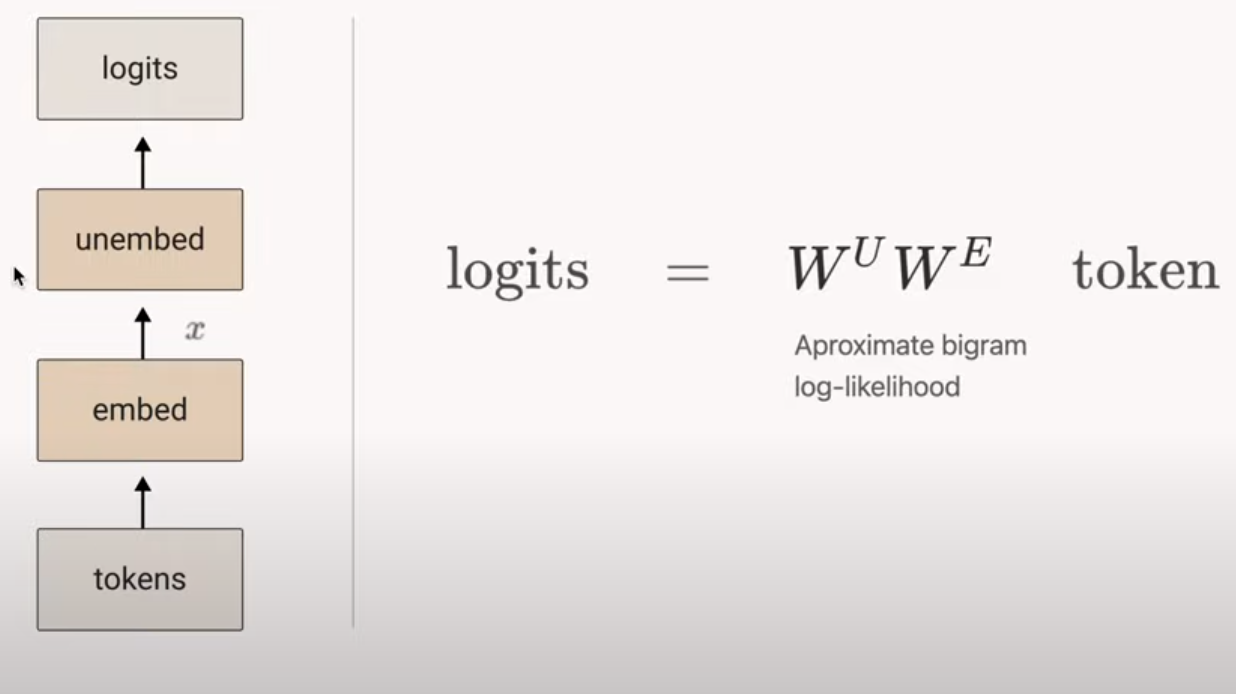
One Layer Attention Transformer is an ensemble of Bigram Statistics and “Skip-Trigrams”
Kronecker Products
During the forward propogation of Transformers, we frequently do two “types” of multiplications
- Multiplying each vector in a Matrix with another Matrix (Eg: to convert tokens to queries / keys)
- Weighted average of the Vectors in a Matrix (Eg: to get the final representation of a token by the weighted average of all the other tokens, assigning weights after attending to them)
We can represent this more intuitively using Kronecker Products!
How is the next token produced?
Let’s see how the One Layer Transformer produces the next token by updating the representation of the Last Produced Token.
To do this, it considers the entire context available to the model.
Path Expansion Trick



The QK & OV Circuits

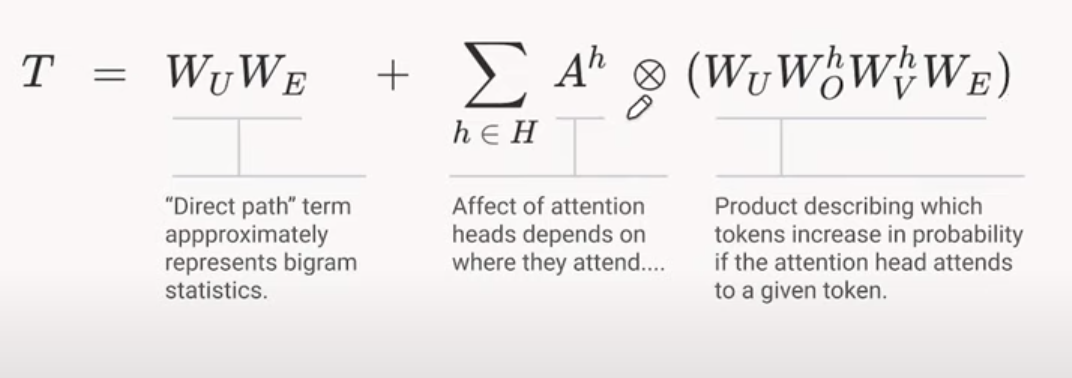
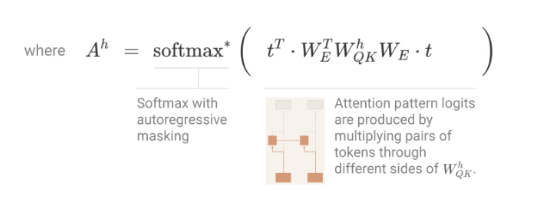
Splitting the computation into two seperable operations

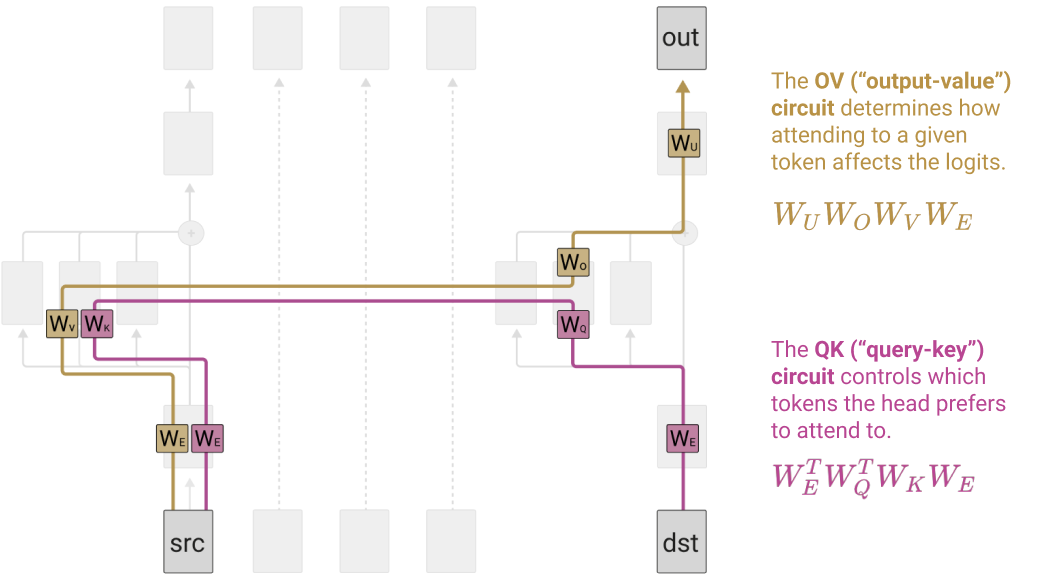
- The Attention Pattern depends on the Source and Destination Token, but once a Destination token has decided how much to “Attend” to a source token, the effect on the output is a function only of that source token.
- If multiple destination tokens attend to the same source token in the same amount, the source token will have the same effect on the Logits for the predicted output token.
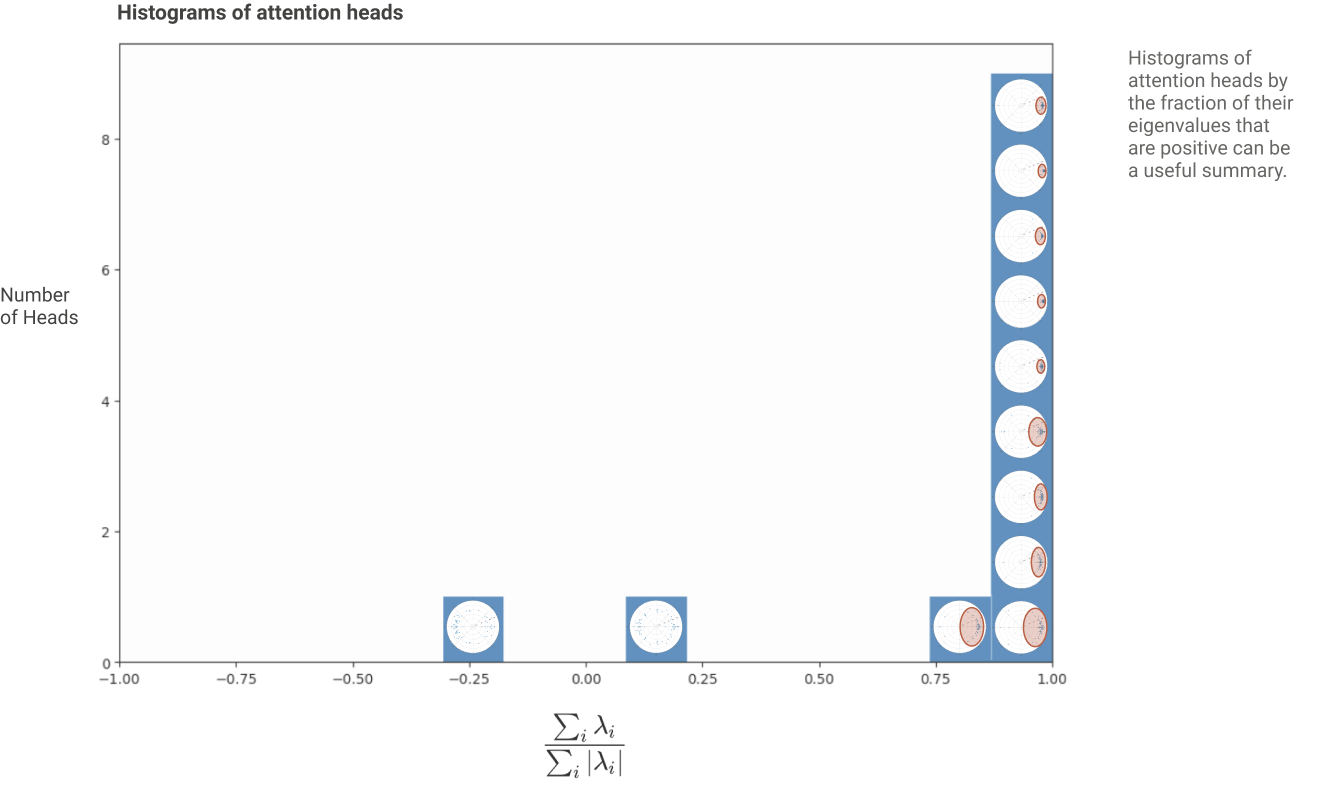
Eigenvalue Analysis
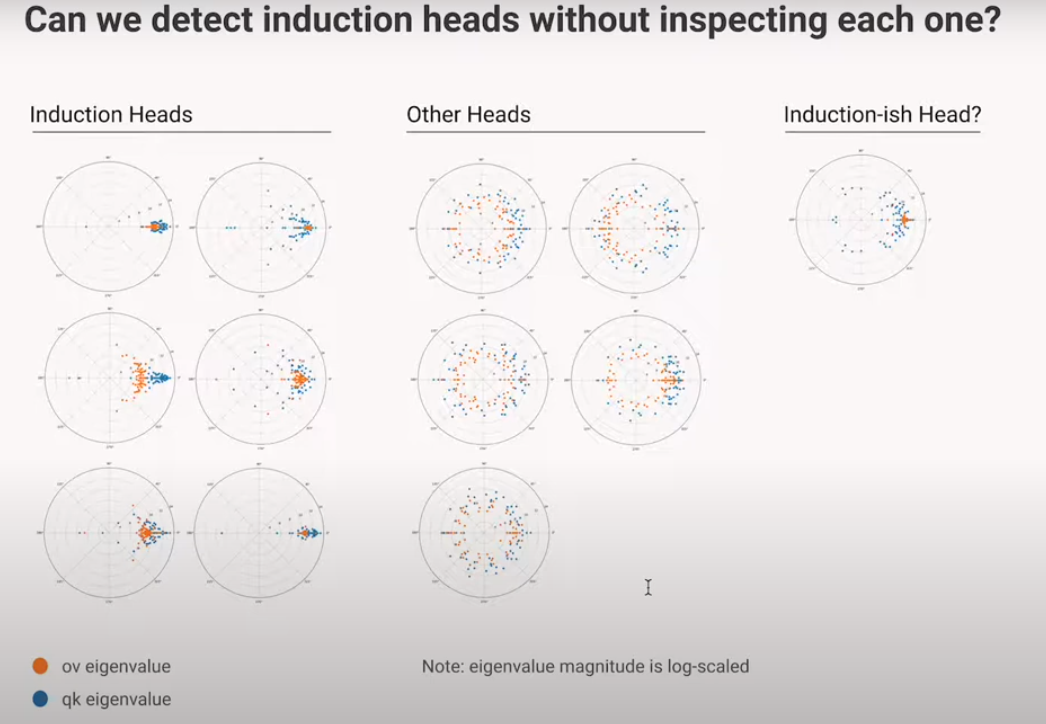
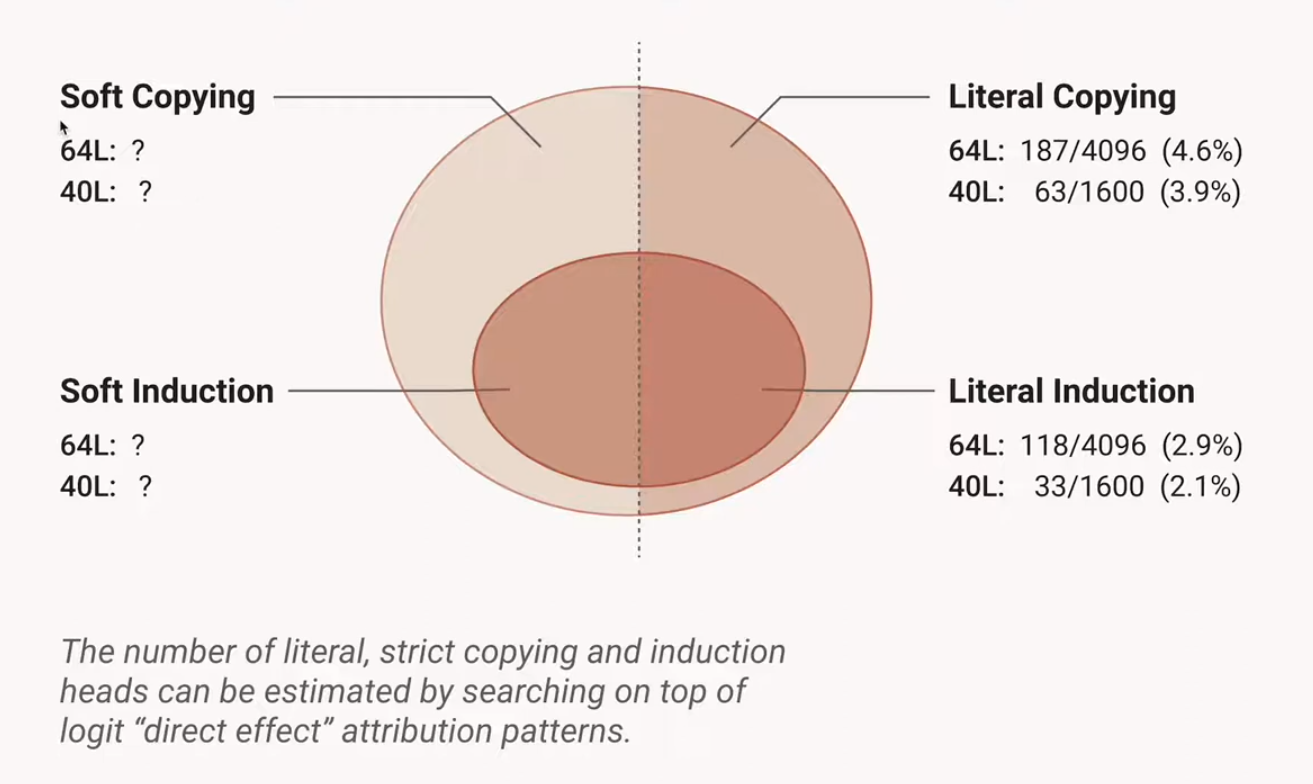
Can we “detect” whether an attention head is “Copying”?
According to the authors, though they don’t provide a formal proof for this, the presence of large, positive Eigenvalues in the OV Circuit is indicative of “Copying”.
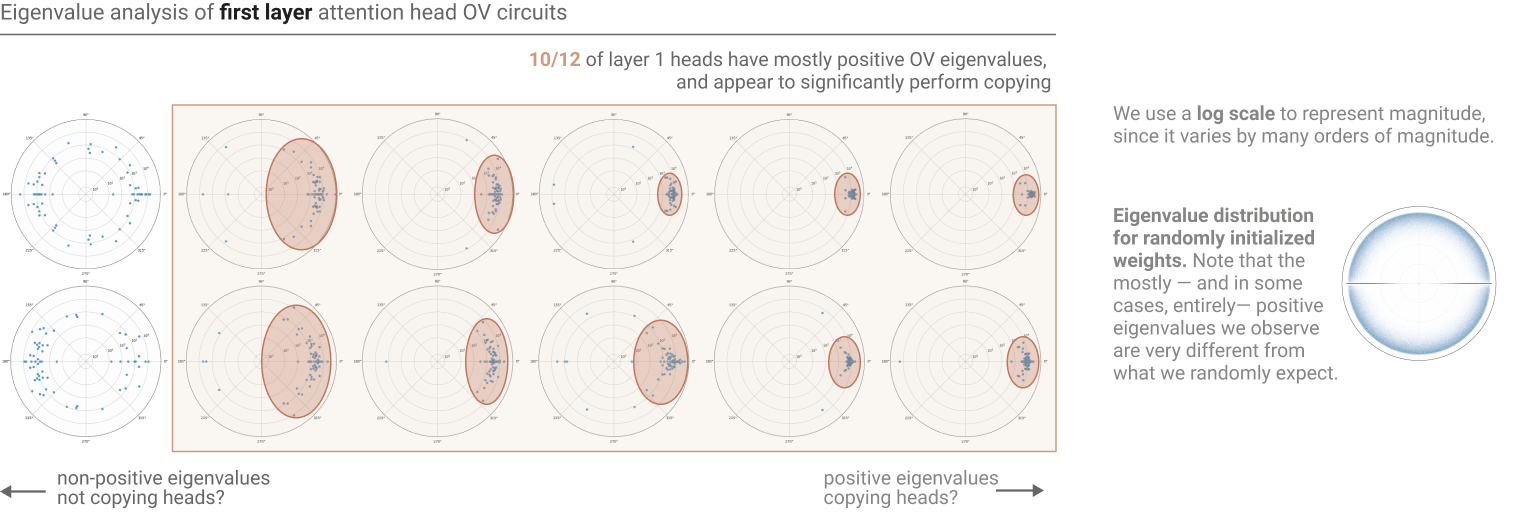
If we plot a histogram of the Attention Heads with the percentage of “Copying” Attention Heads on the X-Axis:
Two Layer Attention Transformer are more expressive!
How do they vary from One Layer only models?
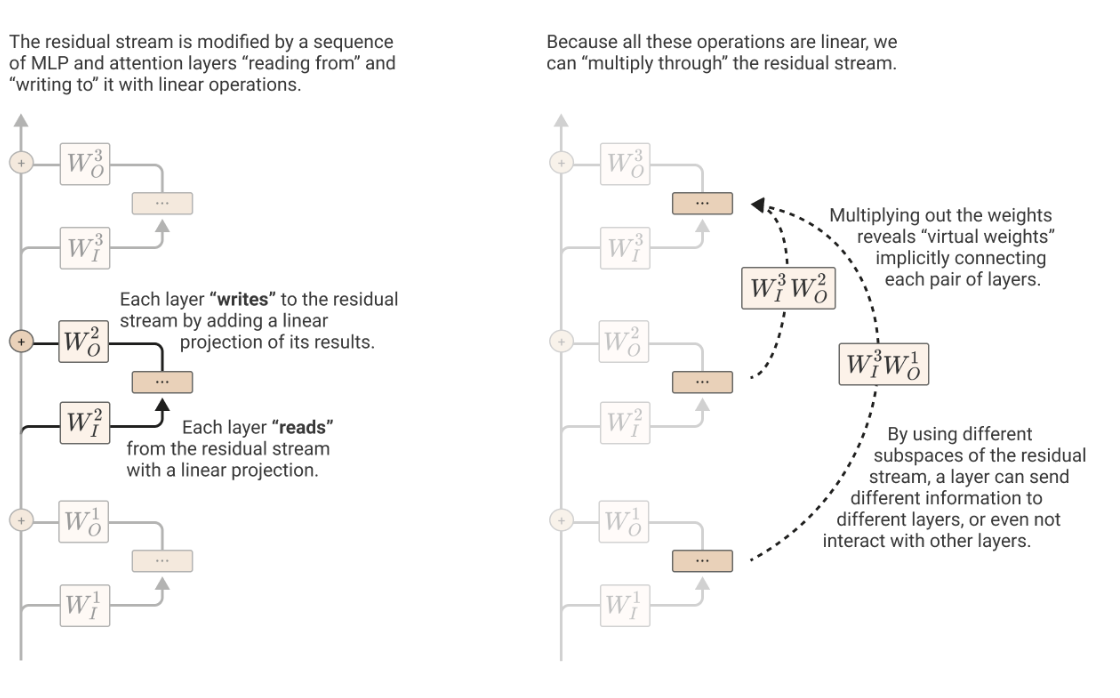
The residual stream is a communication channel. Every Attention head reads in subspaces of the Residual Streams determined by Wq, Wk and Wv and then writes to some subspac determined by Wo.
When Attention Heads compose, there are three options:
- Q-Composition: Wq reads in a subspace affected by a previous head.
- K-Composition: Wk reads in a subspace affected by a previous head.
- V-Composition: Wv reads in a subspace affected by a previous head.
Here, the Q & K composition affect the attention pattern, allowing the second Attention Layer to express much more complex patterns while deciding which token to give attention to.
V composition on the other hand affects what information an Attention Head “moves” when it attends to a given position.
Path Expansion of the O-V circuit
Freezing the Attention Layers as in the 1L case, we see that V-Composition affects the final output.

Path Expansion of the Attention Scores of the QK Circuit
We have written the Attention Pattern in this form earlier in the 1L case.
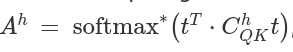
We shall attempt to do the same again. But, Cqk takes a much more complex form indicating that the 2nd Layer can implement very complex attention patterns.

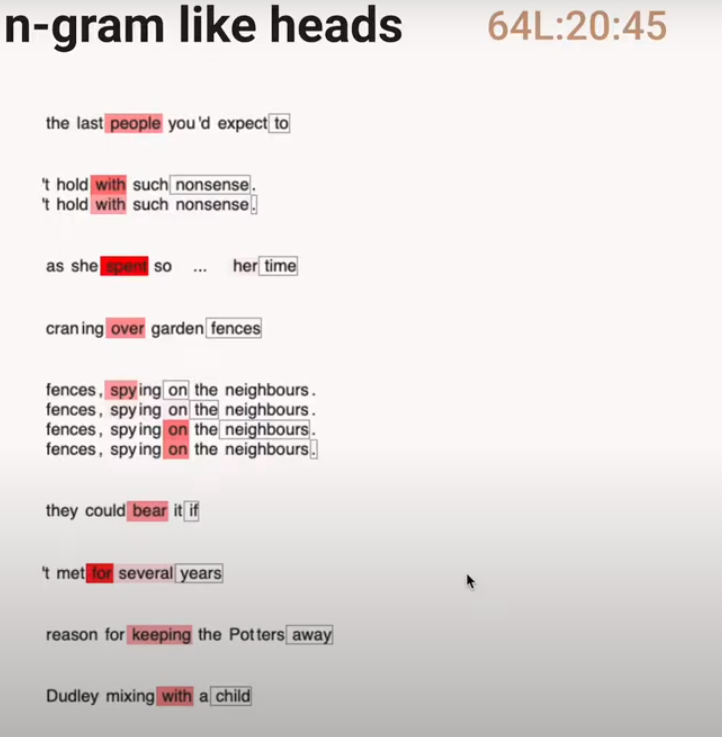
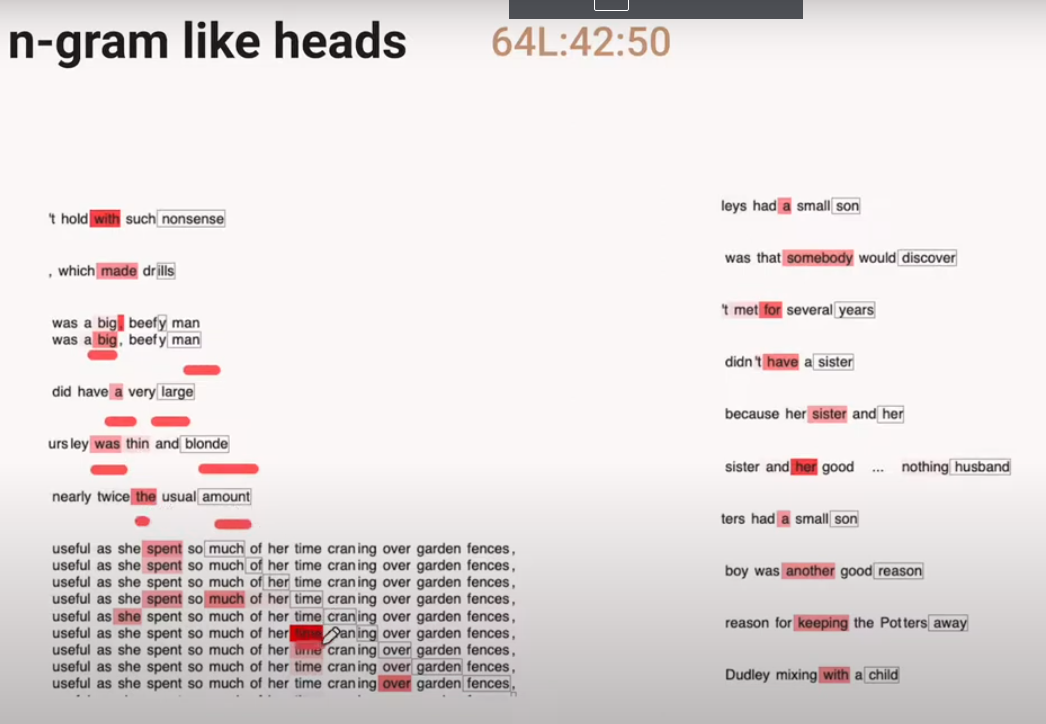
Induction Heads
Let us see an example of how the Attention Heads in a 2L Transformer work.
The Aqua colored Induction Heads often attend back to the previous instances of the token which will come next!
We call these kind of Attention Heads “Induction Heads”!
Induction Heads
Induction heads search over the context for previous examples of the present token. If they don’t find it, they attend to the first token (in our case, a special token placed at the start), and do nothing. But if they do find it, they then look at the next token and copy it. This allows them to repeat previous sequences of tokens, both exactly and approximately.

How do Induction Heads Work?

The Simplest way an Induction Head could be made

Term Importance Analysis


Interesting Visualizations of Induction Heads
<Show the Youtube Video?/>